
Verifying ParamGen, a Climate Model Configuration Tool
Climate models are typically configured with multiple input parameter files to specify model physics, numerics, and other behavior. These files may contain tens to hundreds of parameters with interdependencies and constraints. Therefore, modeling frameworks, such as that of the Community Earth System Model (CESM), include infrastructure libraries that automatically generate default input files corresponding to scientifically vetted or suggested configurations.
In this post, I will introduce one such infrastructure library, called ParamGen. This library supports arbitrary Python expressions for specifying default runtime parameters and values, thereby providing a high level of flexibility, genericity, and extensibility. Initially developed for the MOM6 ocean component in CESM, ParamGen is now used by several additional CESM components. Therefore, it is of high importance that it operates correctly, i.e., absent any undesired and unexpected behavior.
To that end, I will describe an abstract verification model of ParamGen in Alloy, a software modeling and analysis tool with a declarative language that combines first-order logic and relational calculus. I will then evaluate the correctness of ParamGen via Alloy and discuss how abstract models and formal verification can help quickly frame questions and get answers regarding the structure and behavior of our scientific computing applications.
Note: We have recently published this work in a peer-reviewed conference proceedings1: pdf link
ParamGenPermalink
ParamGen is a Python library that generates default input parameter files for CESM components. The following diagram depicts its data flow:
| Figure 1: ParamGen Data Flow. |
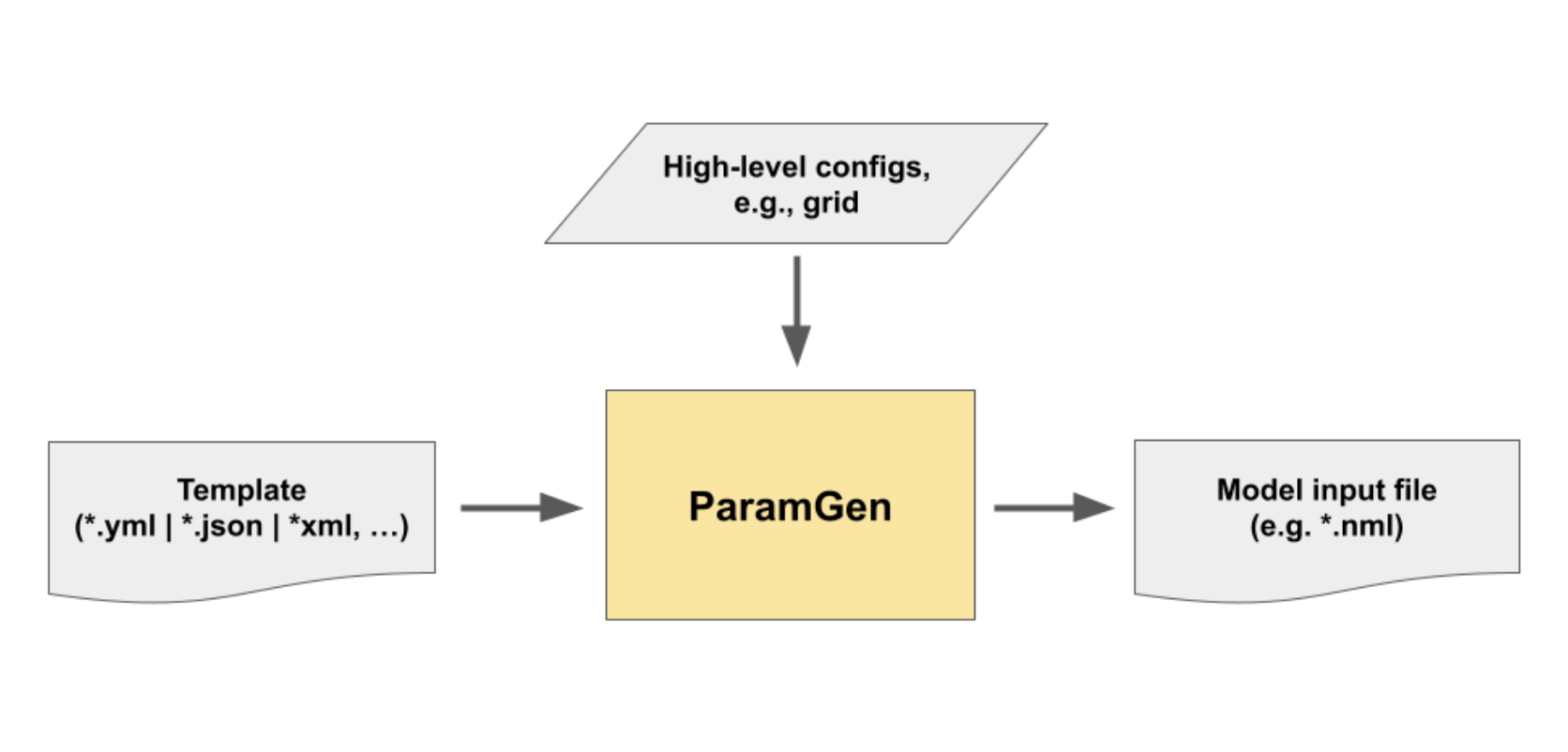 |
In the above diagram, the template corresponds to a data collection that determines the default parameter values
for any given experiment configuration. Templates are to be put together by model developers and are
typically stored in markup formats like yaml, json, or xml. Below is an example template
containing three parameter definitions, (1) NIHALO, (2) NIGLOBAL, and (3) DIABATIC_FIRST:
NIHALO: 2
NIGLOBAL:
$OCEAN_GRID == "g16":
320
$OCEAN_GRID == "t061":
540
DIABATIC_FIRST:
$OCN_GRID in ["g16","t061"]
The first parameter definition corresponds to the simplest case, where a
parameter called NIHALO is always set to 2 regardless of the high-level experiment
configuration. The second parameter, NIGLOBAL, includes two branches. It is
either set to 320 or 540 depending on what the value of OCN_GRID is, which is a
high-level setting determined at startup, i.e., before ParamGen comes into play.
The third parameter DIABATIC_FIRST doesn’t involve multiple branches but its
value is determined by a Python expression: $OCN_GRID in ["g16","t061"]. So, assuming
the OCN_GRID is set to "t061" for a particular experiment, the resulting
input parameter file becomes:
NIHALO = 2
NIGLOBAL = 540
DIABATIC_FIRST = True
In ParamGen nomenclature, this operation of going from a general template
to an experiment-specific input parameter list is called reduce().
Figure 2: The ParamGen reduce() method |
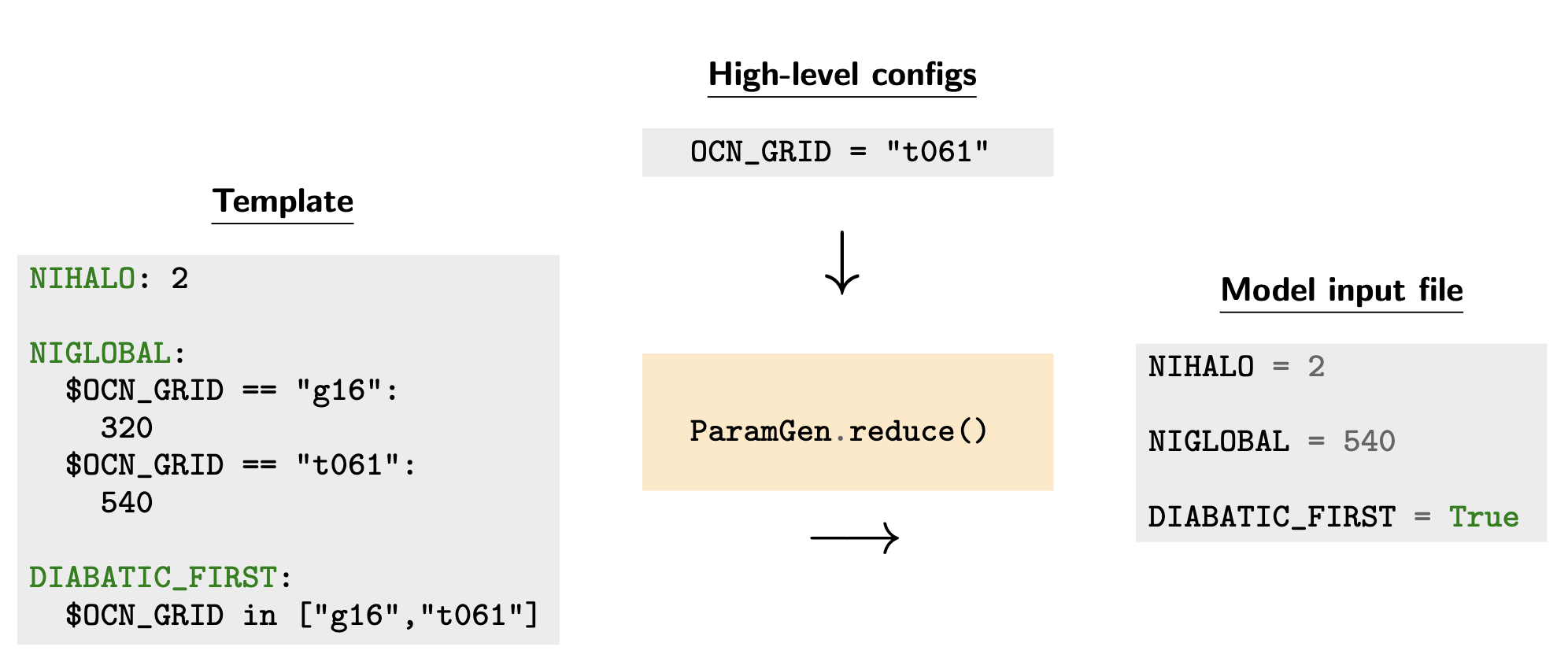 |
In addition to reduce(), below are the definitions of several ParamGen concepts:
- branch:
A set of connected keys and values in a ParamGen template.
Below is an individual branch from the previous ParamGen template:
NIGLOBAL: $OCEAN_GRID == "g16": 320In the above branch, we have two key nodes (
NIGLOBAL) and ($OCEAN_GRID == "g16"). This branch terminates with a value node (320). - guard: Guards are special keys that evaluate to True or False. These
are used as propositions to determine which value gets picked for a particular
variable. For the
NIGLOBALdefinition, we have two guards: ($OCEAN_GRID == "g16") and ($OCEAN_GRID == "t061"). These guards precede the values320and540, respectively. Therefore, depending on which guard evaluates to true, the value ofNIGLOBALgets set to either320or540. - label: Labels are key nodes that do NOT evaluate to True or False. These
are typically used to specify parameter names, e.g.,
NIGLOBAL. Additionally, labels may be used to specify parameter group names and property names. - expandable variable: These variables correspond to high-level experiment
settings that are to be set by the user before ParamGen comes into play. Expandable
variables are preceded by the
$sign., and are replaced by their actual values during the execution of thereduce()method. In Figure 2, for example,$OCN_GRIDgets replaced by"t061"during the execution ofreduce().
Below diagram summarizes these main concepts used in ParamGen:
| Figure 3: ParamGen Terminology |
 |
ParamGen is flexible!Permalink
- Expandable variables and arbitrary Python expressions may appear anywhere in a template, e.g., in labels, guards, or values.
- There can be multiple labels along a branch, e.g., to specify the namelist group names and, subsequently, the parameter names.
- There can be multiple (nested) guards along a branch.
- There is no restriction on the ordering of guards and labels. For instance, guards can appear before, after, or in between labels.
ParamGen schema:Permalink
- There must be at least one label along a branch.
- If a key is a guard, all the neighboring keys (at the same level) must also be guards.
Here is an example template that violates the second schema rule:
NIGLOBAL:
description:
"grid points in x-dir."
$OCN_GRID == "g16":
320
This is because a label (description) and a guard ($OCN_GRID == "g16") appear
at the same level. The following alternative template specification resolves this issue.
NIGLOBAL:
description:
"grid points in x-dir."
value:
$OCN_GRID == "g16":
320
ParamGen reduce() method:Permalink
The reduce() method is the main operator in ParamGen. It generates input
parameter files for a given experiment based on a general template.
This method works as follows:
- Traverse all branches recursively.
- Apply in-place modifications:
- expand variables.
- evaluate formulas.
- impose guards.
Reliability of ParamGen:Permalink
Two main factors complicate efforts to ensure ParamGen’s reliability:
- Due to its recursive nature and in-place modifications, the
reducealgorithm is relatively complex. - There are many different template layouts to be considered since ParamGen allows for great flexibility in specifying templates.
With these sources of complexities in mind, ParamGen is routinely tested via comprehensive unit and integration tests to ensure reliability. However, testing is incomplete.
“Testing can be used to show the presence of bugs, but never to show their absence.”
— Edsger W. Dijkstra
As a complementary approach to testing, formal methods may offer further assurance in software reliability efforts. In the next section, I will use Alloy, a formal methods tool, to model and analyze ParamGen.
Alloy Model of ParamGenPermalink
We begin the development of our Alloy model by specifying the structure of the system. In ParamGen, the main structure is the data template, which is stored in nested dictionaries. As a simplistic language, Alloy doesn’t include compound data structures like Python dictionaries. We, therefore, specify an abstract dictionary structure as follows:
sig Dict {
contents: set Key
}
abstract sig Key {
var map : lone Dict+Value
}
sig Value {}
The Dict signature declaration above models Python dictionaries. Its contents field corresponds
to a set of Keys. The map field of the Key signature similarly associates keys with either Value instances
(whose signature declaration is quite straightforward) or Dict instances in the case of nested
dictionaries.
To represent the two different Key types, i.e., Labels and Guards, we extend the above abstract Key definition as follows:
sig Label extends Key {}
sig Guard extends Key {}
sig Root extends Key {}{
no this.~contents
}
In addition to Labels and Guards, the above code block includes another extension of the
Key signature called Root, whose instances correspond to references of Root dictionaries,
i.e., those that are not contained by other dictionary instances.
Having defined all the necessary pieces of the structure, we can ask Alloy to generate arbitrary model instances satisfying the structure specification. Below is one such instance.
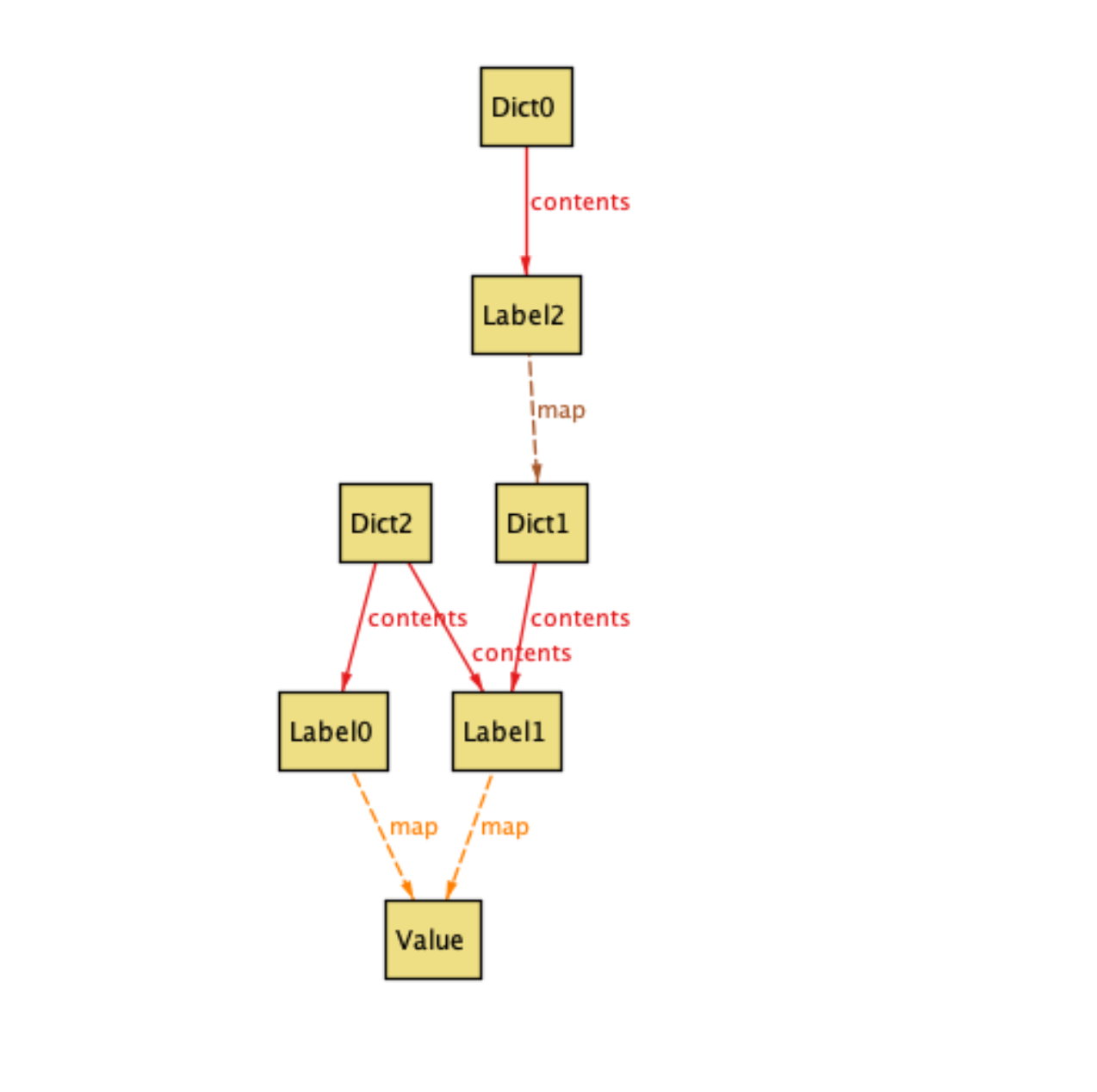
In this first model instance, two issues stand out:
Label1is contained by two different dictionary instances,Dict1andDict2.- Similarly,
Valueis mapped to by two different label instances,Label0andLabel1.
Let’s eliminate these identified flaws by adding two constraints to the model:
// each item can have at most one key
all i: Dict+Value |
lone i.~map
// each key can be contained by only one dict
all k: Key |
lone k.~contents
Subsequently, let’s instruct the Alloy analyzer to generate another model instance:
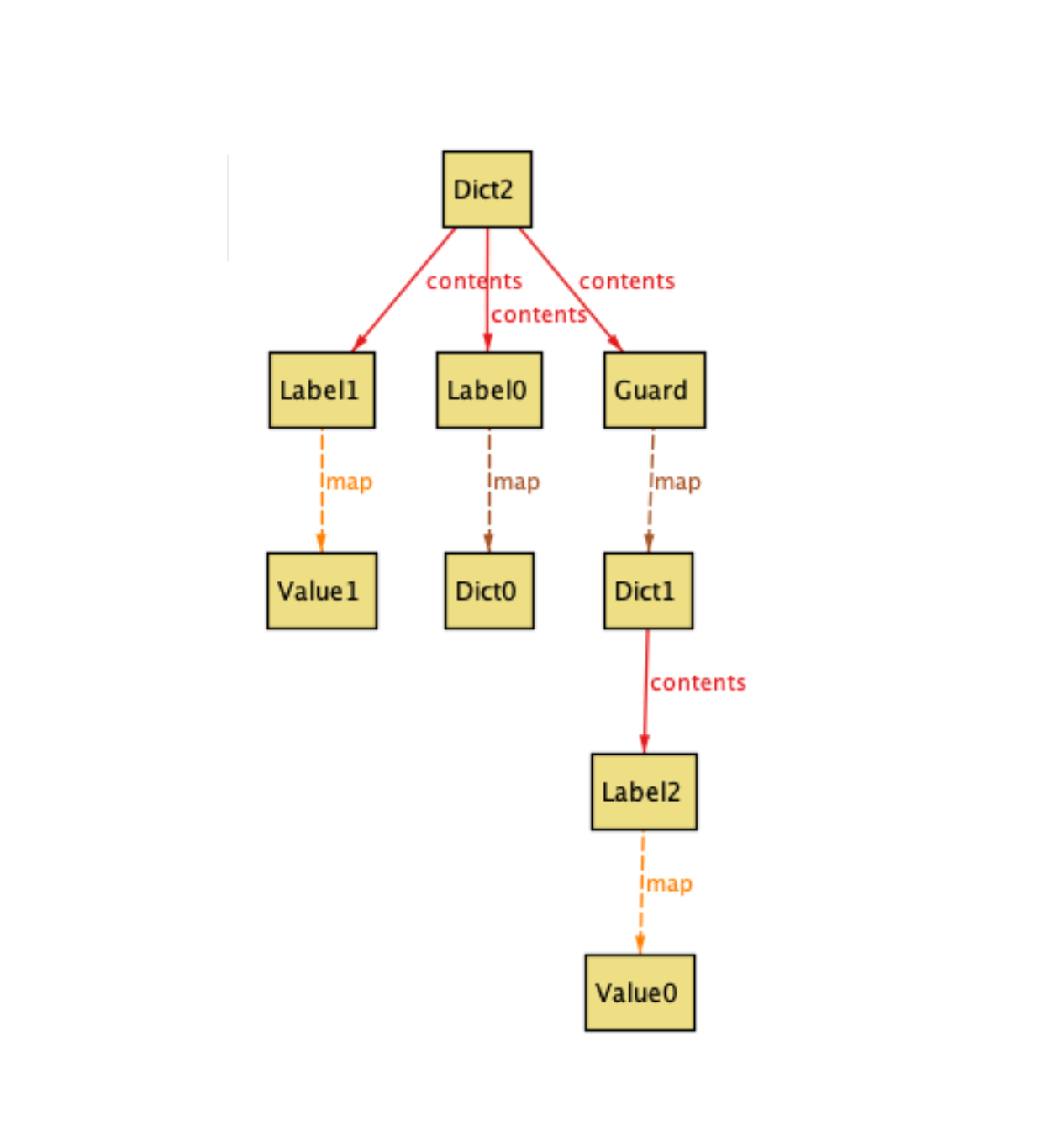
While this instance doesn’t exhibit the previous flaws, it reveals another
issue: Dict2 contains both Guard and Label instances. As described previously,
this behavior violates ParamGen template schema. To eliminate this
flaw, here is an additional constraint.
// if one content is a guard, all contents must be guards
all d: Dict |
{some Guard & d.contents implies d.contents in Guard}
After a few more iterations of adding constraints and visually inspecting instances, we end up with the following full list of constraints.
pred invariants{
// map.*contents relation is acyclic
no iden & ^(map.*contents)
// each item can have at most one key
all i: Dict+Value |
lone i.~map
// each key can be contained by only one dict
all k: Key |
lone k.~contents
// if one content is a guard, all contents must be guards
all d: Dict |
{some Guard & d.contents implies d.contents in Guard}
// all values must be preceded by a label
all v: Value |
some v.^(~map.*~contents) & Label
}
Having fully modeled the ParamGen structure, the next task is to model the dynamic
aspects, and mainly the reduce() method. Without going into many details, I am
presenting the Alloy model (left panel) and the Python implementation (right panel)
of reduce() side by side:

Notice that the Alloy model of reduce() looks very similar to the actual Python
implementation. This is because we are at an algorithm design level rather
than lower-level implementation details, which are hidden behind function calls
such as impose_guards() and expand_vars().
Now let’s look at Alloy and Python versions of impose_guards():

Now that we are getting into the weeds, the difference between Alloy and Python
versions is quite significant. The comparison of expand_vars() is even more
striking:

While the Python version of expand_vars() includes a series of regex operations and
string manipulations, the Alloy version includes a single line of expression
specifying what expand_vars() should accomplish, rather than how it should do so in a step-by-step
fashion. Simply, the Alloy specification says that the intersection of a
given expression expr and the set of variables to expand (varsToExpand) must be an empty set
at the next (virtual) state.
Abstract Representation in Modeling SoftwarePermalink
As demonstrated above, abstract representation of lower-level details allows us to focus on high-level software and algorithm design aspects. As a result, we can quickly build prototypes and diagnose design flaws at the early stages of development. Incrementally, we can add more details to our abstract models to quickly explore the structure and behavior of our scientific computing applications.
“The hard part of building software is the specification, design, and testing of conceptual construct, not the labor of representing it and testing the fidelity of the representation.”
— FP Brooks. “No silver bullet”. 1987.
“What matters is the fundamental structure of the design. If you get it right then subsequent development is likely to flow smoothly. If you get it wrong, there is no amount of bug fixing and refactoring that will produce a reliable, maintainable, and usable system.”
— D Jackson. “The essence of software”. 2021.
Back to ParamGen DynamicsPermalink
After having modeled the reduce() method, we are ready to instruct Alloy to generate
an arbitrary instance that is subject to an arbitrary state transition as a result of
executing reduce():
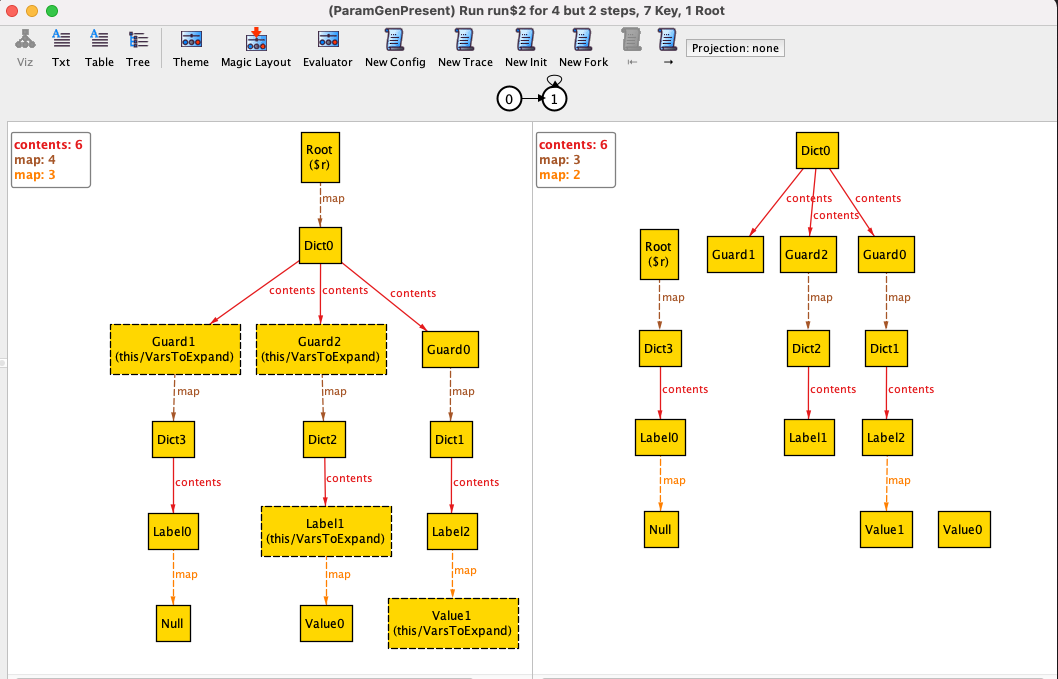
In the initial state (left panel), the root dictionary, which happens to be named
Dict0 contains three guards, Guard1, Guard2, and Guard3.
On the right panel, the Alloy analyzer illustrates an arbitrary next state after running
reduce(). In this example of a next state, Guard1 appears to have been picked as the
guard that evaluates to true, and so Dict3 becomes the new root dictionary. Also notice
that all expandable variables are removed (i.e., replaced by their actual values) in this
final state.
Exhaustive AnalysisPermalink
One major strength of Alloy, and of formal methods in general, is the ability to check for
all cases and transitions in an exhaustive manner. So far, we have visually inspected only a
handful of model instances and transitions.
To check that our model specification satisfies
certain safety conditions at all times (within a given bound), let’s define a predicate
containing all the postconditions and run the check command:
pred reduce_is_safe[r:Root] {
reduce[r] implies {
// All invariants still remain true
invariants and
// The result of postcondition should be a dict
r.map' in Dict
// check properties of active columns
all ai: r.*(map'.*contents) {
// all labels map to some Values or Dictionaries
{ai in Label implies ai.map in Value+Null+Dict}
// no active guard remains
ai not in Guard
// all keys should lead to a value
{ai in Key implies some ai.^(map.*contents) & Value}
// all values should have a label (varname)
{ai in Value implies some ai.^(~map.*~contents) & Label}
// no remaining vars to expand
ai not in VarsToExpand'
}
}
}
assert postconditions {
all r: Root |
reduce_is_safe[r]
}
check postconditions for 8 but 2 steps
Running the above check command confirms that no postcondition is violated within the given bound:

Benefits of specification and software modelingPermalink
Using the Alloy specification of ParamGen, I have identified and addressed design flaws in template handling and preconditions. So, rigorous error checking is one major benefit. Another major benefit of specification and software modeling is it helps us think abstractly and better understand the systems we develop.
“Specifying a system helps us understand it. It’s a good idea to understand a system before building it, so it’s a good idea to write a specification of a system before implementing it.” — L Lamport. “Specifying Systems”. (2002)
“Code is a poor medium for exploring abstractions.” — D Jackson. “Software Abstractions”. (2006)
As the above quotes suggest, it is ideal to specify a system before developing it. But that’s not always possible in scientific computing. Sometimes, we are handed over codes developed by others. Sometimes, we underestimate complexities. And oftentimes, we work with legacy code.
But specification and modeling may be useful at later stages of development as well.
After modeling ParamGen in Alloy, my understanding of ParamGen increased
tremendously (even though I was the original developer). Consequently, I was able to refactor
the reduce() method to increase code clarity and halve the number of lines of code.
SummaryPermalink
- Testing is crucial, but incomplete.
- Formal methods can be complementary to testing.
- Abstract models of scientific software are useful and effective!
- Scientists and engineers are accustomed to working with models anyway.
- With automatic, push-button analysis, one can focus on modeling and design aspects.
- Design aspects matter. More so than lower-level implementation details.